데이터 정규화 - skearn StandardScaler
Contents
거리를 측정하는 모델은 feature 간의 scale이 다른게 영향을 주지 않도록 정규화가 필요하다. sklearn의 StandardScalier 를 알아보자.
핵심 요약
sklearn.preprocessing에 여러 scaler가 준비되어 있음fit_transform()으로 테스트셋에 대해 fit 과 transform 수행transform()으로 테스트셋에 대해서 정규화 수행- 원래의 스케일로 변환해주는
inverse_transform()도 있음
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
# fit + transform
scaler.fit_transform(X_train)
# transform
scaler.transform(X_test)
# inverse stransform
scaler.inverse_transform(sample)
정규화의 필요성
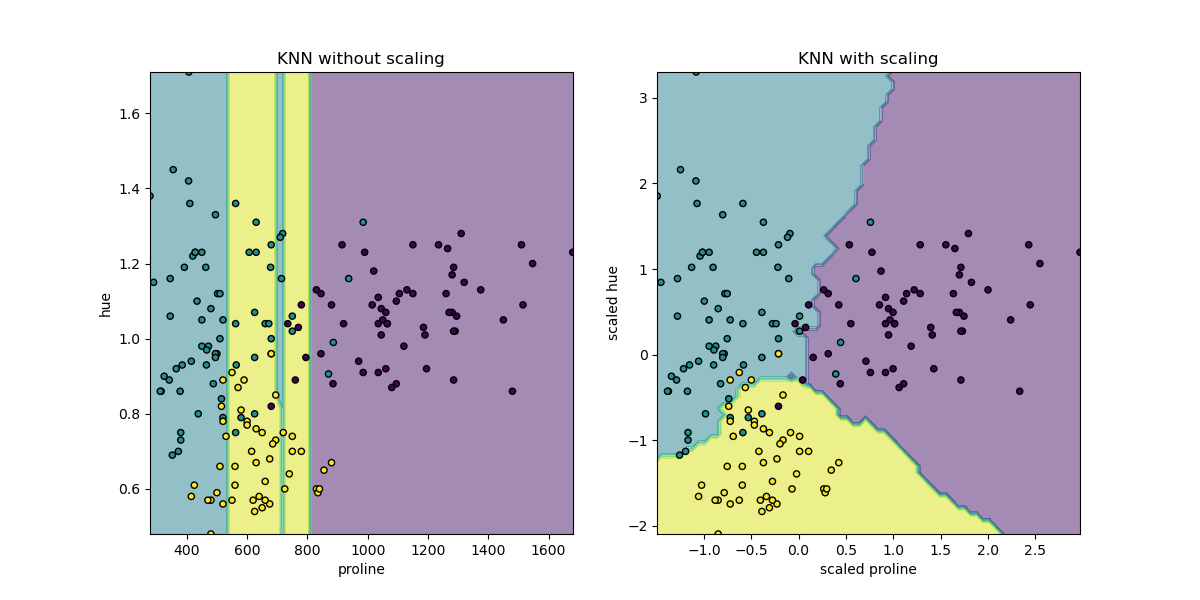
왼쪽의 산포도를 보면 x축의 범위는 [0, 1700] 인데, y축은 [0, 2] 범위 안에 있다.
두 점간의 거리를 잰다고 했을때, y값의 차이는 x값의 차이에 비해 아주 작을 것이서, 거의 영향을 주지 못하게 된다.
오른쪽은 scale 을 맞춰준 상황이다. 이제 두 feature가 비슷한 조건으로 학습에 사용될 수 있다.
sklearn의 정규화 클래스
scikit learn 사이트의 Compare the effect of different scalers on data with outliers 에서 주요 scaler 들이 어떻게 값을 바꿔주는지 보여주고 있다.
- StandardScaler : 평균 0, 표준편차 1 이 되게 scaling
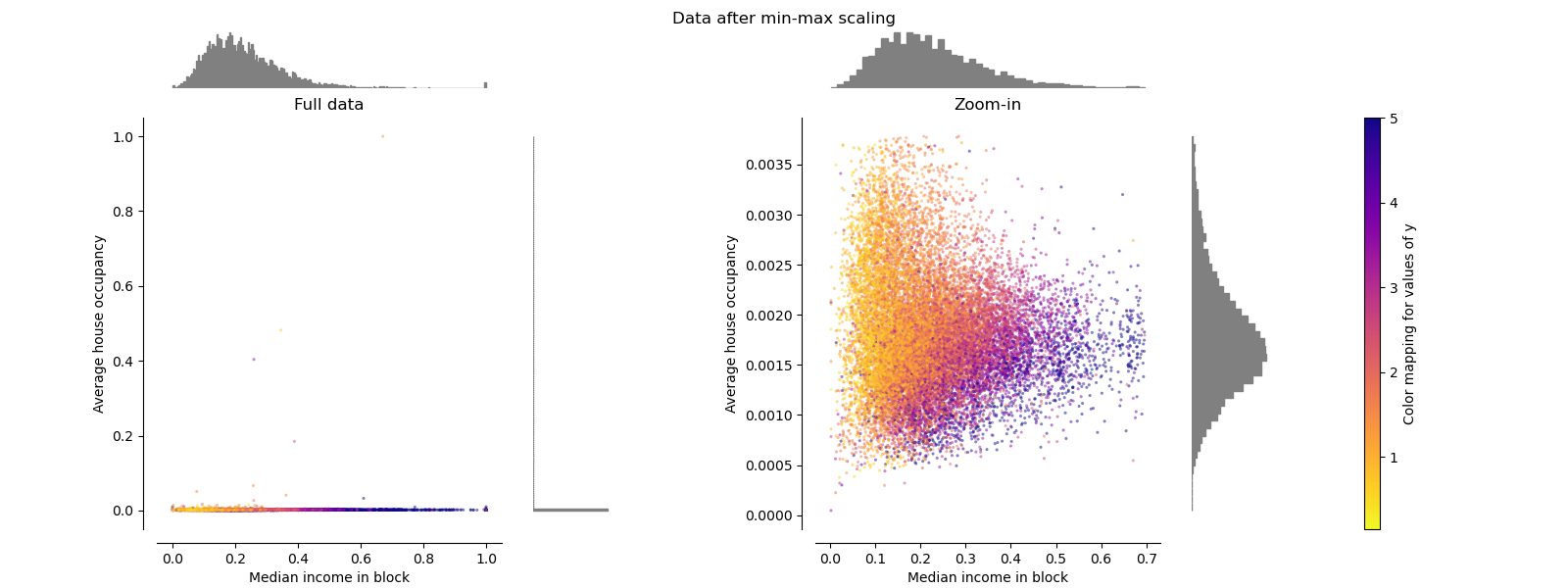
MinMaxScaler : 최소값 -> 0, 최대값 -> 1 이 되도록 scaling [0, 1]
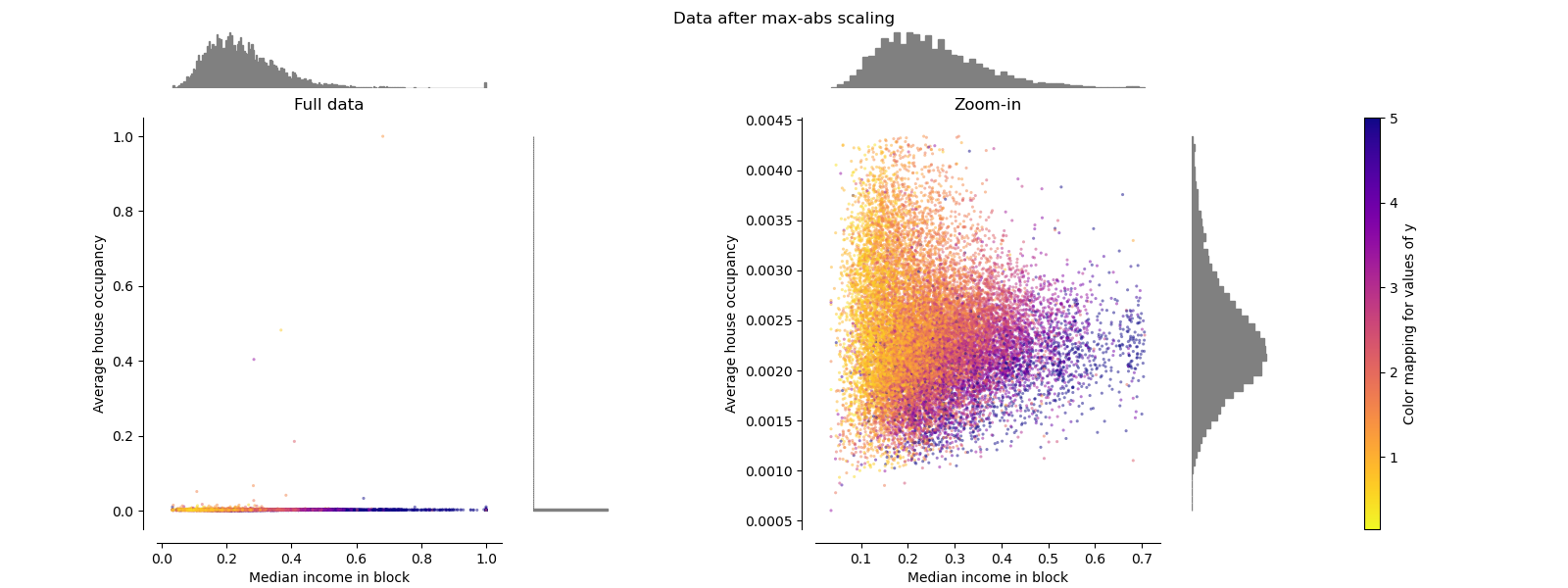
MaxAbsScaler : 최대절대값 -> 1 이 되도록 scaling [0, 1]
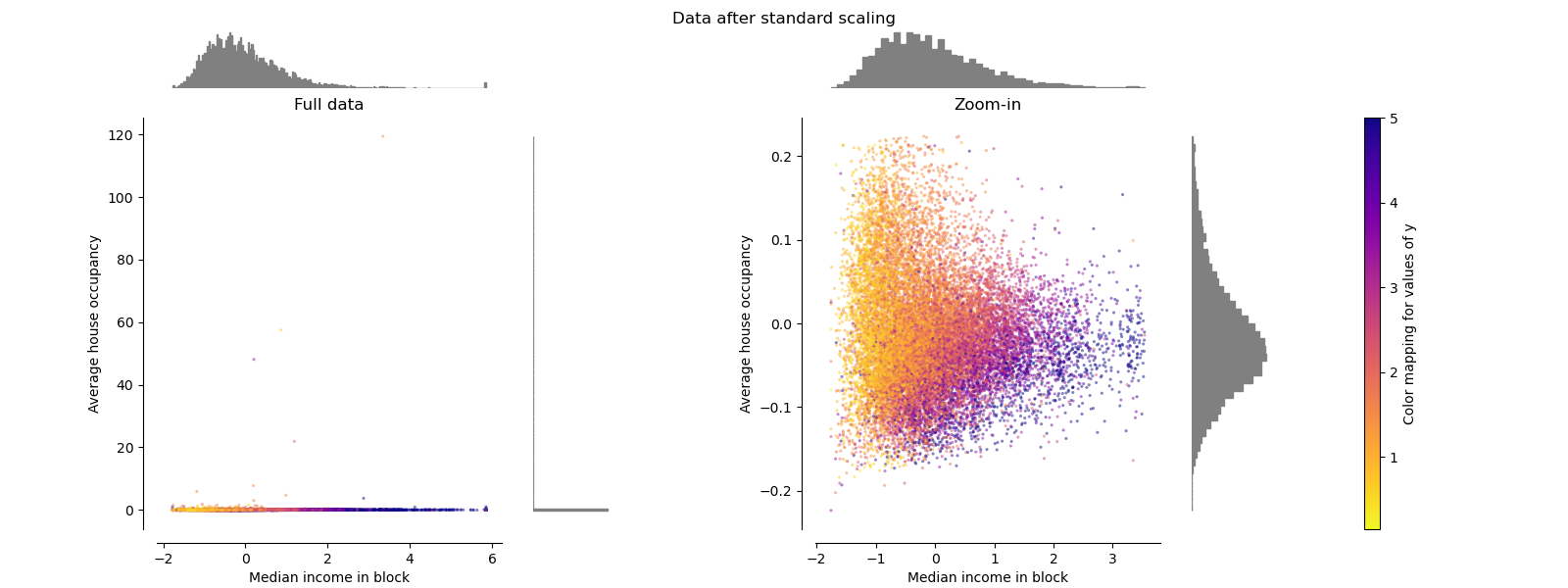
StandardScaler 적용 예시
Click here to view this notebook in full screenReference
- {scikit-learn API} StandardScaler
- {scikit-learn Example} Importance of Feature Scaling
- {scikit-learn Example} Compare the effect of different scalers on data with outliers